Evidence-based practice (EBP) is an approach to clinical decision-making in which the best available evidence is used, together with the practitioner’s expertise and the patient’s preferences, to arrive at the decision most likely to have a beneficial outcome.1 Figure 1 illustrates this concept, with three key factors combined to make a clinical decision. Research has shown that, at least in medicine, EBP is more effective in terms of improved patient outcomes than clinical decision-making that does not seek to use best evidence.2
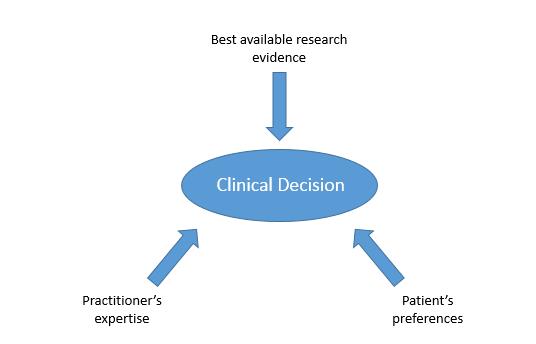
Figure 1: Three key factors influencing a clinical decision
Optometrists are involved, either independently or in shared care, in decisions that are likely to have important consequences for patients’ visual and general health. The adoption of an evidence-based approach to clinical decision-making in optometry is therefore important and is taking place throughout the profession, with some core competencies now specifying EBP3 and evidence-based clinical guidelines being made available to practitioners.4
EBP means that the best available evidence is brought in to any decision such as to refer, recommend treatment, prescribe or do nothing. Key to EBP is therefore understanding the nature of evidence, and the meaning of ‘best’. In the context of evidence-based clinical decision-making, best evidence is widely considered to be the most reliable research. However, research is not available for every clinical decision and information from a range of sources may be used in the decision-making process.
There is a connection between the ‘best available evidence’ and ‘practitioner’s experience and expertise’ aspects of EBP. The best available evidence is sought by the practitioner, and once known it becomes part of that practitioner’s knowledge and expertise, yet can of course be updated at any point in the future.
In clinical decision-making, optometrists have been found to use sources of information such as undergraduate education, postgraduate and continuing education, professional magazines and information from manufacturers.5,6 An important question is whether these sources are likely to provide reliable evidence. ‘Best’ evidence would be the most reliable, and this depends on the extent to which it may be flawed. It is reasonable to suppose that a few years after graduation at least some of the practitioner’s knowledge from undergraduate education is likely to have been superseded by new research findings.
For example, until recently most optometry graduates would have ‘known’ that amblyopia cannot be treated beyond about the age of 10 years, but recent research raises questions about this knowledge.7 Information presented at a continuing education conference or in a professional magazine might summarise the research and update the practitioner’s knowledge, but the reliability of this information may be unclear until full details are available.
The practitioner needs to judge the reliability of the available information in order to find the best available evidence, and use this as part of decision-making. For the wide range of clinical questions in optometric practice there may be relevant research evidence in some cases but not in others. For example, the question, ‘Is refractive correction alone an effective treatment for amblyopia in children?’ may arise, and the practitioner may be able to find several relevant research articles. On the other hand, for the question ‘Is refractive correction alone an effective treatment for amblyopia in adults?’ the practitioner may find little or no research evidence at all. In the latter case, the practitioner may need to make a clinical decision based not on research but on existing knowledge, experience and the patient’s needs and wishes. In order to determine whether research is available and which provides the best, most reliable, information, the practitioner must be able to find and appraise research evidence.8 This article focuses on the appraisal of research by identifying various factors that affect its reliability as a basis for clinical decision-making.
Appraising research evidence
Research evidence is available in the form of various types of study design, from case studies to randomised controlled trials, in addition to reviews. The evidence provided by a piece of research may be classified according to its ‘level’ as an indicator of the extent to which it is likely to be reliable. Table 1 shows some study designs and their characteristics. Low level studies would include individual case studies in which, for example the response of one or a small number of patients to a treatment may be reported.

Table 1: Study designs and their characteristics
Case studies of this kind provide information which is not highly reliable as a basis for clinical decision-making. This is because a small number of individuals have been included in the research. The study has not included a wide range of individuals, and does not reflect the correspondingly wide range of responses to treatment. This range is illustrated by almost any research report in which average data are shown along with an indication of the range around this point, such as with error bars showing standard deviation, confidence intervals or another measure indicating the extent of variation around the average.
The patient seen in practice may not behave in the same way as the average patient in a study sample, so even if the research finds that (on average) a treatment is effective, this may not be the case for the patient in practice. This is true when we consider the findings of any research, but when the sample is small we have little or no indication of whether the finding is likely to apply to other individuals, reducing the reliability of results as the basis of clinical decision-making.
A randomised controlled trial (RCT) would be considered high level because attempts to control bias are included in the study design. Specifically, first, participants are randomly
allocated into two or more groups. This helps to ensure that each group includes a similar mix of people, with similar variations in age, gender, race, motivation, personality and other factors that might affect the outcome of the study.
Second, each group represents a different intervention, with a minimum of two, one being the treatment and another being a control. The control is a comparison which may be no treatment at all or may be a placebo treatment, the latter being an intervention which should be indistinguishable from the treatment except that it does not have the ingredient that is hypothesized to be effective. For example, saline eye drops might provide a good placebo comparison for a study on the effectiveness of a special formulation of drops for dry eye, as long as the two look, smell and feel identical. This is because treatment and control groups should be unaware of the type of group to which they have been allocated. They should not know that they are in a control group, for example, because in this case the individuals are unlikely to expect an effect and may behave accordingly, while those who know they are in a treatment group may show an effect and this may be due in part to the fact that it is expected.
If the participants are unaware of their grouping, the study is said to be masked (or ‘blinded’) and this is a further check on bias, increasing the extent to which the findings are likely to be reliable. Further, the study may be double-masked, in which case not only the participants but also the researchers are unaware of grouping. Masking is particularly important in a study using subjective tests such as visual acuity, near point of convergence, or accommodative facility, for example, because expectations by the participant or the researcher could affect the results.
Systematic reviews are generally considered to be at the highest level in this hierarchy, and since they are given this high status it is important to know why, and to understand the difference between these and other reviews. The methods used in a systematic review include measures that aim to ensure the review is free of bias, including a protocol (which should be published prior to the start of the review process) ensuring that the researchers adhere to their approach regardless of their findings during the review.
In addition, more than one reviewer decides on the relevance and quality of the included studies, and set criteria are used to judge quality. On the other hand, reviews that do not use this type of approach may be subject to bias because the criteria used to judge the included studies may not be fixed so could change as the review progresses, and this judgment could be biased by the reviewers’ prior knowledge, experience or preconceptions.

While the level of a research study provides an indication of the reliability of its findings, it is important to bear in mind that a study considered to be high level, based on study design, may prove to have less reliability than expected once we look at it in detail. For example, an RCT may indeed be controlled, but we may find that it was not masked, or that the control was not adequate. For example, a control group in which participants have no intervention at all is not directly comparable to a treatment group with an intervention, because the control group is aware that nothing happened and the difference between the two groups is not only that one had a treatment but also that one could anticipate a treatment effect while the other would not.
In addition, it is important to appreciate that these levels of research evidence are based in part on the idea that clinical research involves testing the efficacy of a treatment. In many cases this is true, but in some cases the research relevant to our clinical question may be related to diagnosis or prognosis, for example. In such cases, a randomised controlled trial would not be an appropriate study design and a design that may otherwise be considered to be of relatively low level would be more relevant. Levels of evidence should be viewed with this in mind.
The level of research evidence provides an indicator of likely research quality, then, but is not definitive. To judge the reliability of research evidence, the practitioner needs to be able to identify factors indicating bias. The fact that published research may be biased or otherwise flawed may seem surprising, given the fact that most research publications are peer reviewed. The peer review process involves the research report being appraised by experts in the field, who may identify flaws or bias and recommend against publication. It would seem reasonable to assume that such a system would exclude flawed research, but this is not the case and there have been well publicised examples of the failures of this system.9 It is therefore very important for the practitioner to be able to appraise research prior to its use in clinical decision-making. In view of this, it is worth considering some of the forms of bias we might find in optometric and other research literature.
Forms of bias in research
- The research should include people who are representative of the population in question. For example, in a study on the severity of symptoms of convergence insufficiency, if we included only people who present to optometric practices with these symptoms we may under or overestimate severity since there may be many other patients who do have symptoms but have not discussed these with their optometrist (perhaps with lower symptom severity) and others who have bypassed the optometrist and gone straight to another practitioner (perhaps with more severe symptoms). This could be a source of bias in which our sample of people may not be representative of the population with this condition. One form of this type of bias is known as selection or sampling bias, in which the study sample is not representative of the population in question, and can arise if we choose participants rather than recruit them in a more random fashion.
- It is important to be aware that the behaviour of people involved in research may be influenced by a number of factors, leading to performance bias. For example, we may see an apparent effect of treatment, but this could be a placebo or nocebo effect, in which a positive or negative effect is expected by the participant, who behaves accordingly. Similarly, it may reflect a Hawthorne effect, in which the participant behaves differently when observed (during the research) than in a more natural situation.10 These differences in the participant’s behaviour could affect outcome measures such as visual acuity and other clinical tests with a subjective element, in addition to questionnaire responses.
- One of the challenges of clinical research is that of attrition – the withdrawal of participants during the study – which may occur for a number of reasons. It may skew the results if a larger number of people are lost from one group than from another, or if a particular type of person is lost from the study (perhaps those for which the treatment had a negative effect, or who could not commit the time needed for the study). This is known as attrition bias, and may give rise to misleading results.
- Some clinical research is conducted and/or funded by a person or organisation with a conflict of interest, such as someone with a financial interest in a therapeutic or diagnostic method tested in the research. This would normally be stated within a research paper (typically in a dedicated section at the end of the paper). It is important to look for this, as it is a potential source of bias, and alerts the reader to look for clear indicators that the research findings are reliable.
- Some forms of bias cannot be easily identified by reading a research publication, but may still exist and skew the reported results. For example, selective reporting bias can occur when the researchers present some but not all of their findings, perhaps only those that show an effect of treatment, giving a distorted picture of efficacy. In addition, it is important to be aware of publication bias, which is the bias toward publication of research showing significant effects, with less publication of research showing no effect. This leads to a possibly skewed perception of the effectiveness of available treatments, for example.
Almost all clinically relevant research papers include indicators of statistical significance, the extent to which the results show an effect or an association. One or more measures and numbers are usually presented to show the strength of this significance, such as a t-test, analysis of variance or odds ratio.
Commonly a p value is used, and this is the probability that the result would occur if the null hypothesis (that there is no effect) were true. A p value of less than 5% (0.05; probability of one in 20 that the result has occurred by chance) is conventionally used to indicate that the effect is statistically significant (see Armstrong et al, 201111 for guidelines on reporting statistics in clinical studies related to optometry).
The conclusion drawn by the researchers is usually based in part on a statistic such as a p value. However, it is important to bear in mind that there is a difference between statistical significance and clinical significance.
To use a hypothetical example, in a study on the effect of a new treatment on age-related macular degeneration, there may be two similar groups of people with the disease at similar severity and acuity levels at the beginning of the study. After using the treatment (in one group) or a placebo control (in another group), at the end of the study affected eye acuity improves in the treatment group from 0.6 to 0.48 and in the control group from 0.6 to 0.54. Perhaps the improvement is found to be statistically significantly greater in the treatment than control group (with a p value of less than 0.05).
However, for the purposes of clinical decision-making it would be important to consider whether the absolute improvement (of 0.12 logMAR in the treatment group) is likely to be significant in terms of a meaningful improvement for the patient. This is a question of clinical significance, is likely to vary among patients, and is an important consideration alongside the statistical significance to decide whether this is a clinically important result.
The appraisal of research evidence takes time, which limits its feasibility as a component of clinical decision-making. However, a number of resources are available to facilitate this process. The Cochrane organisation,12 including the Cochrane Eyes and Vision Group, provides an open access database of systematic reviews addressing clinical questions, some of which are relevant to optometry.
As outlined earlier, the methods used in creating systematic reviews include several measures that minimise bias; the Cochrane reviews use stringent methods and are likely to provide the practitioner with high quality evidence in a digestible format, since the processes of searching for and appraising evidence have been completed. However, there are currently many optometric clinical questions that are not addressed by Cochrane or other systematic reviews, so in many cases the practitioner does not have this option.
Evidence-based clinical guidelines such as those provided by the College of Optometrists4 provide another valuable resource of evidence for clinical decision-making. However, guidelines address only a subset of the clinical scenarios encountered in practice, and the practitioner should be able to understand the basis for those guidelines, so an ability to find and appraise the relevant evidence remains important.
The process of research appraisal can be facilitated by using a Critical Appraisal Tool (CAT), various versions of which are available freely online, some generic and some customised for particular types of research design. For example, the Critical Appraisal Skills Programme13 (CASP) makes CATs freely available for the appraisal of research papers describing randomised controlled trials as well as studies testing diagnostic methods, cohort studies and other study designs.
CATs are checklists with questions prompting the practitioner to consider various factors that might cause or minimise bias, and to decide whether the research in question is likely to be reliable as a basis for clinical decision-making. For example, the CASP CAT for an RCT asks the question ‘Was the assignment of patients to treatments randomised?’ This question ensures the reader checks randomisation was carried out; if not, it becomes apparent that the groups may not be comparable, and this can be taken into account in judgment of reliability.
Similarly, the CASP CAT for a diagnostic study asks ‘Was there a comparison with an appropriate reference standard?’ prompting the reader to check whether a gold standard was used to compare with the diagnostic test in question. Questions of this kind are important in the appraisal of research evidence because they remind us to consider various points that relate to the quality of the research and the extent to which the findings may be biased.
Even with these resources, time is a major barrier to applying EBP in practice, and it may be necessary to consider strategies to ensure awareness of the best evidence relevant to common clinical scenarios and anticipated clinical questions. For example, as outlined above many optometrists use information from continuing education as a basis for clinical decision-making.
After attending a seminar or reading a CET article in which new information (such as a new treatment or diagnostic method) is discussed, the relevant research evidence base could be sourced and appraised in anticipation of any related clinical scenario, so that the practitioner has an awareness of current best evidence when the situation arises. In addition, while attending the seminar or reading the article, it is important to ask questions similar to those found on a CAT, so that the new information is essentially being appraised while listening/reading.
Summary
The ability to critically appraise reports of research relevant to optometric practice is an essential skill for evidence-based clinical decision-making. Appraisal involves questioning the research methods and identifying sources of bias, and is facilitated by the use of critical appraisal tools.
Resources such as systematic reviews provide high level evidence which may address a specific clinical question, and as such can be very helpful for the busy practitioner. However, even high level evidence may not always be high quality, so critical appraisal skills remain vital. They should be used when attending seminars or reading professional magazine articles, as well as research.
Dr Catherine Suttle is a senior lecturer in Optometry and Visual Science, City, University of London.
References
1 Satterfield JM, Spring B, Brownson RC, Mullen EJ, Newhouse RP, Walker BB, Whitlock EP (2009) Toward a transdisciplinary model of evidence-based practice. Milbank Q. 87(2):368-90.
2 Emparanza JI, Cabello JB, Burls AJ (2015) Does evidence-based practice improve patient outcomes? An analysis of a natural experiment in a Spanish hospital. J Eval Clin Pract. 21(6):1059-65.
3 Kiely PM, Slater J (2015) Optometry Australia entry-level competency standards for optometry 2014. Clin Exp Optom 98(1): 65-89.
4 www.college-optometrists.org/en/professional-stand... Accessed 04/11/2016
5 Suttle CM, Jalbert I, Alnahedh T. (2012) Examining the evidence base used by optometrists in Australia and New Zealand. Clin Exp Optom. 95(1):28-36.
6 Lawrenson JG, Evans JR (2013) Advice about diet and smoking for people with or at risk of age-related macular degeneration: a cross-sectional survey of eye care professionals in the UK. BMC Public Health. 13:564.
7 Tsirlin I, Colpa L, Goltz HC, Wong AM. (2015) Behavioral training as new treatment for adult amblyopia: A meta-analysis and systematic review. Invest Ophthalmol Vis Sci. 56(6):4061-75.
8 Graham AM (2007) Finding, retrieving and evaluating journal and web-based information for evidence-based optometry. Clin Exp Optom. 90(4):244-9.
9 Bohannon J (2013) Who’s afraid of peer review? Science 342(6154): 60-65.
10 Benedetti F, Carlino E, Piedimonte A. (2016) Increasing uncertainty in CNS clinical trials: the role of placebo, nocebo, and Hawthorne effects. Lancet Neurol. 15(7):736-47.
11 Armstrong RA, Davies LN, Dunne MC, Gilmartin B. (2011) Statistical guidelines for clinical studies of human vision. Ophthalmic Physiol Opt. 31(2):123-36.
12 www.cochrane.org Accessed 04/11/2016
13 www.casp-uk.net Accessed 15/11/2016